DeepInfra raises $107M Series B to scale the inference cloud — read the announcement

Imagine going to an art gallery where paintings tell their stories. That’s what "Talking Images" do in practice. This tutorial shows you how to make art speak using DeepInfra models. We are going to use:
1-) deepseek-ai/Janus-Pro-7B
2-) hexgrad/Kokoro-82M
Setting Up Environment
First, let’s set up your environment. You’ll need these packages. Here’s the content of requirements.txt:
gradio
requests
python-dotenv
pillow
scipy
numpy
Venv Environment Setup
Show Venv Tutorial
python -m venv venv && (venv\Scripts\activate.bat 2>nul || source venv/bin/activate) && pip install -r requirements.txt
Create .env File
Next, create a .env file in your project folder. Copy your DEEPINFRA_API_TOKEN into it. Your .env file should look like this:
DEEPINFRA_API_TOKEN=your-api-token-here
Replace your-api-token-here with your actual DeepInfra API token.
The Code
Here’s the Python code that makes your images talk. It uses Janus-Pro-7B to describe the image and Kokoro-82M to turn that description into audio.
import os
from io import BytesIO
import gradio as gr
import base64
import requests
from dotenv import load_dotenv, find_dotenv
from scipy.io import wavfile
import numpy as np
_ = load_dotenv(find_dotenv())
def analyze_image(image) -> str:
url = "https://api.deepinfra.com/v1/inference/deepseek-ai/Janus-Pro-7B"
headers = {"Authorization": f"bearer {api_token}"}
buffered = BytesIO()
if image.mode == "RGBA":
image = image.convert("RGB")
format = "JPEG" if image.format == "JPEG" else "PNG"
image.save(buffered, format=format)
files = {"image": ("my_image." + format.lower(), buffered.getvalue(), f"image/{format.lower()}")}
data = {
"question": "I am this image. You must describe me in my own voice using 'I'. State my colors, shapes, mood, and any notable features with precise detail. Examples: 'I have clouds,' 'I contain sharp lines.' Be vivid, thorough, and factual."
}
response = requests.post(url, headers=headers, files=files, data=data)
return response.json()["response"]
def text_to_speech(text: str) -> tuple:
url = "https://api.deepinfra.com/v1/inference/hexgrad/Kokoro-82M"
headers = {
"Authorization": f"bearer {api_token}",
"Content-Type": "application/json"
}
data = {
"text": text
}
response = requests.post(url, json=data, headers=headers)
res_json = response.json()
audio_base64 = res_json["audio"].split(",")[1]
audio_bytes = base64.b64decode(audio_base64)
audio_io = BytesIO(audio_bytes)
sample_rate, audio_data = wavfile.read(audio_io)
return sample_rate, audio_data
def make_image_talk(image):
description = analyze_image(image)
sample_rate, audio_data = text_to_speech(description)
return sample_rate, audio_data
if __name__ == "__main__":
api_token = os.environ.get("DEEPINFRA_API_TOKEN")
interface = gr.Interface(
fn=make_image_talk,
inputs=gr.Image(type="pil"),
outputs=gr.Audio(type="numpy"),
title="Art That Talks Back",
description="Upload an image and hear it talk!"
)
interface.launch()
Final Look
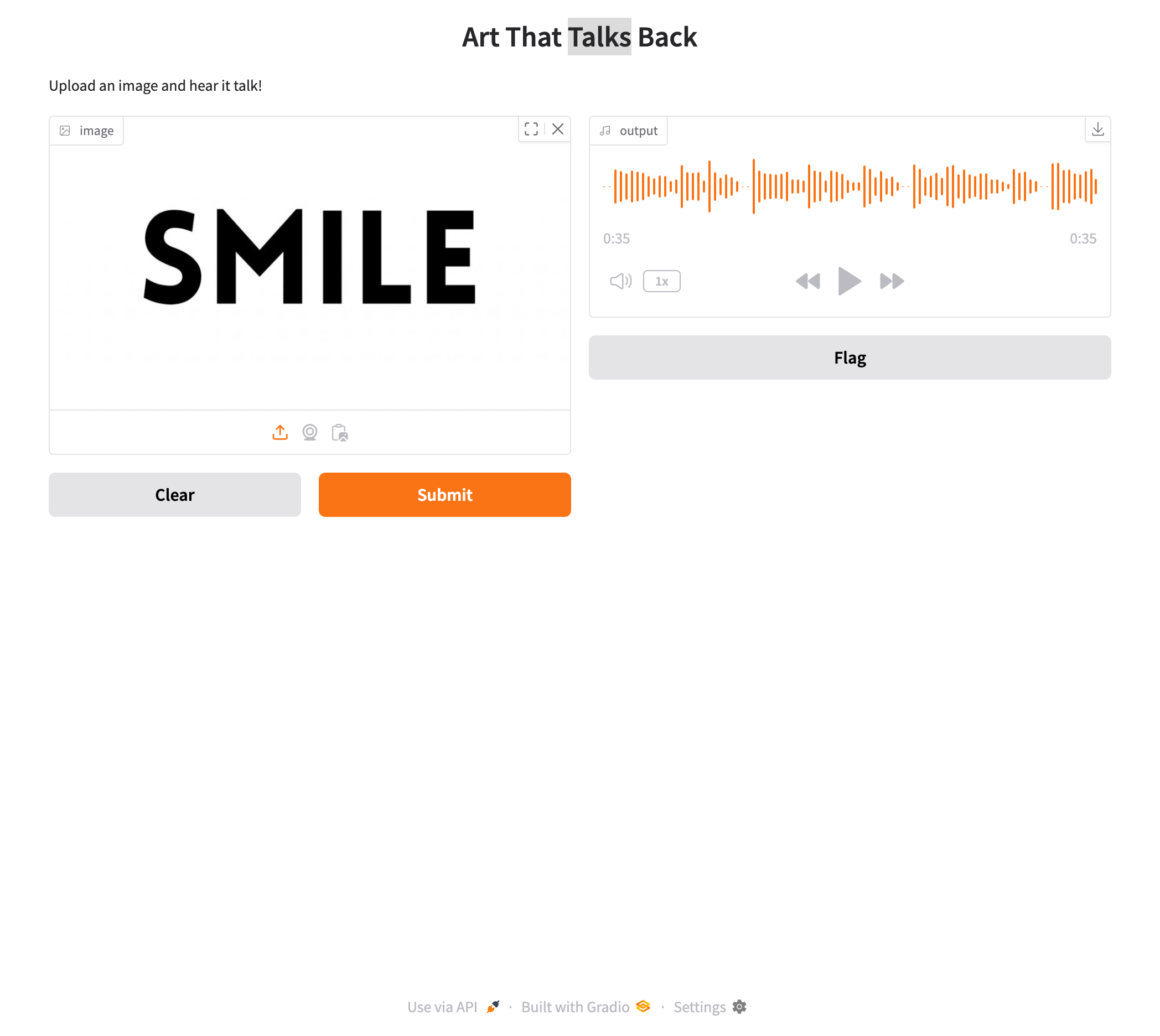
Try It Yourself!
Ready to hear your own art talk back? Grab yourself an image, run the code, and upload it. Do not forget to follow us on Linkedin and on X.
 Nemotron 3 Ultra, 3.5 Content Safety and ASR models are now live on DeepInfra platform.Nemotron 3 Ultra and Nemotron 3.5 Content Safety are live on DeepInfra as of today. Here's what they are and why we think they're worth your attention.
Nemotron 3 Ultra, 3.5 Content Safety and ASR models are now live on DeepInfra platform.Nemotron 3 Ultra and Nemotron 3.5 Content Safety are live on DeepInfra as of today. Here's what they are and why we think they're worth your attention. How Open Source AI Is Closing the Gap<p>At the end of 2023, the gap between open-weight and closed-source AI models was real and easy to describe. If you wanted the best performance on reasoning, language understanding, or multi-step problem solving, you paid for a proprietary API. Open models were useful, capable for many tasks, and dramatically cheaper to run but they were […]</p>
How Open Source AI Is Closing the Gap<p>At the end of 2023, the gap between open-weight and closed-source AI models was real and easy to describe. If you wanted the best performance on reasoning, language understanding, or multi-step problem solving, you paid for a proprietary API. Open models were useful, capable for many tasks, and dramatically cheaper to run but they were […]</p>
 NVIDIA Nemotron 3 Super on DeepInfra: 120B MoE Model<p>NVIDIA’s Nemotron 3 Super runs 120 billion parameters while activating only 12 billion per token — a ratio that makes a real difference when orchestrating multiple agents in parallel. It’s built on a novel architecture called LatentMoE, a hybrid of Mamba-2, Mixture-of-Experts, and Attention layers designed from the ground up for agentic, reasoning, and long-context […]</p>
NVIDIA Nemotron 3 Super on DeepInfra: 120B MoE Model<p>NVIDIA’s Nemotron 3 Super runs 120 billion parameters while activating only 12 billion per token — a ratio that makes a real difference when orchestrating multiple agents in parallel. It’s built on a novel architecture called LatentMoE, a hybrid of Mamba-2, Mixture-of-Experts, and Attention layers designed from the ground up for agentic, reasoning, and long-context […]</p>



© 2026 DeepInfra. All rights reserved.