DeepInfra raises $107M Series B to scale the inference cloud — read the announcement
 Latest article
Latest articleOne click gives you a dedicated, isolated AI agent, pre-wired to fast inference and ready to work the moment it boots. No VMs, no SSH hardening, no patching. From $13/month, and idle is free.
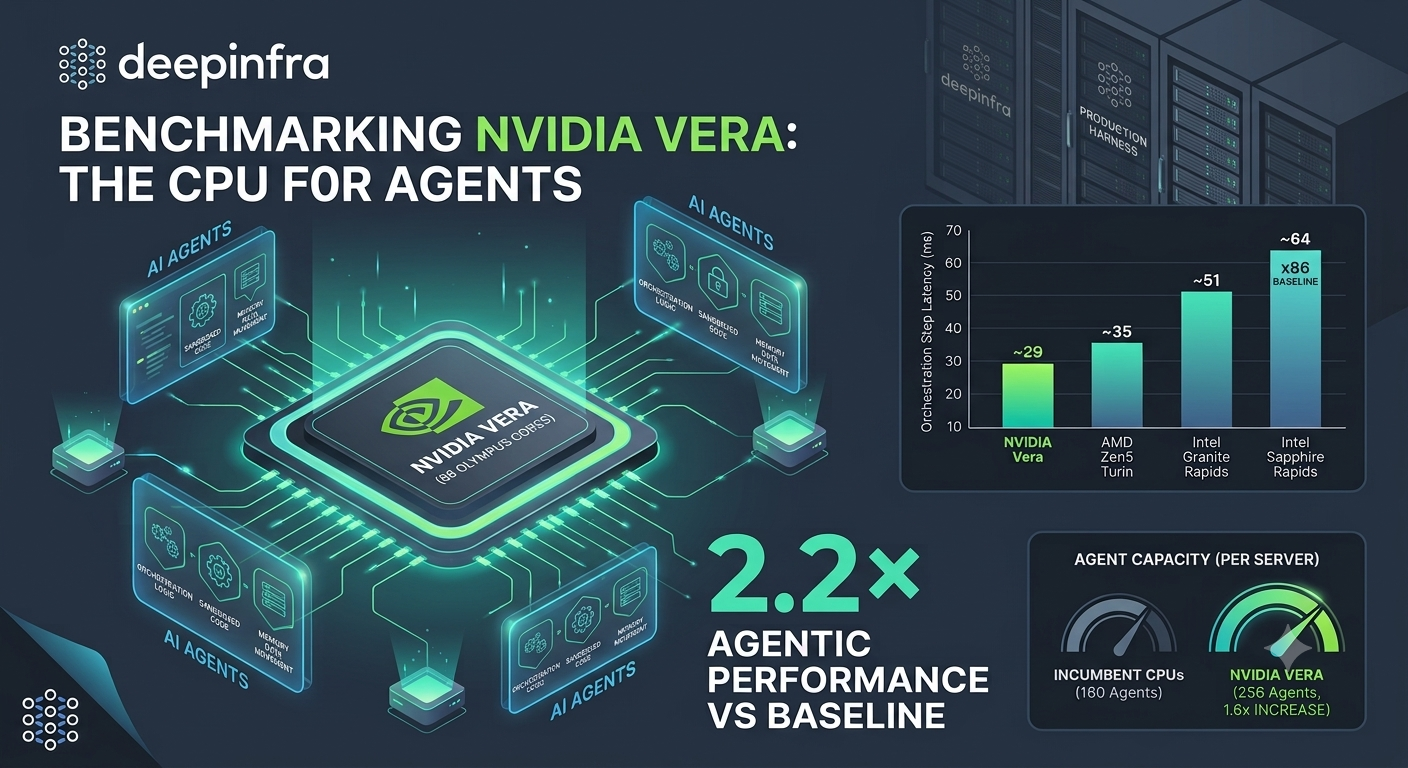 Published on 2026.07.21 by DeepInfraWe Benchmarked NVIDIA Vera, the CPU for Agents. Here's What We Measured
Published on 2026.07.21 by DeepInfraWe Benchmarked NVIDIA Vera, the CPU for Agents. Here's What We MeasuredDeepInfra runs AI agents in production, so when NVIDIA built a CPU for agents, we measured it ourselves with our own harness, our own agent, and a methodology we locked before the hardware arrived.
 Published on 2026.07.16 by Aray SultanbekovaDeepInfra Now Serves NVIDIA Nemotron 3 Embed: Frontier Retrieval for RAG and Agents
Published on 2026.07.16 by Aray SultanbekovaDeepInfra Now Serves NVIDIA Nemotron 3 Embed: Frontier Retrieval for RAG and AgentsDeepInfra now serves NVIDIA Nemotron 3 Embed, the industry's leading open embedding model for enterprise search and agentic retrieval, available today in both 8B and 1B sizes.
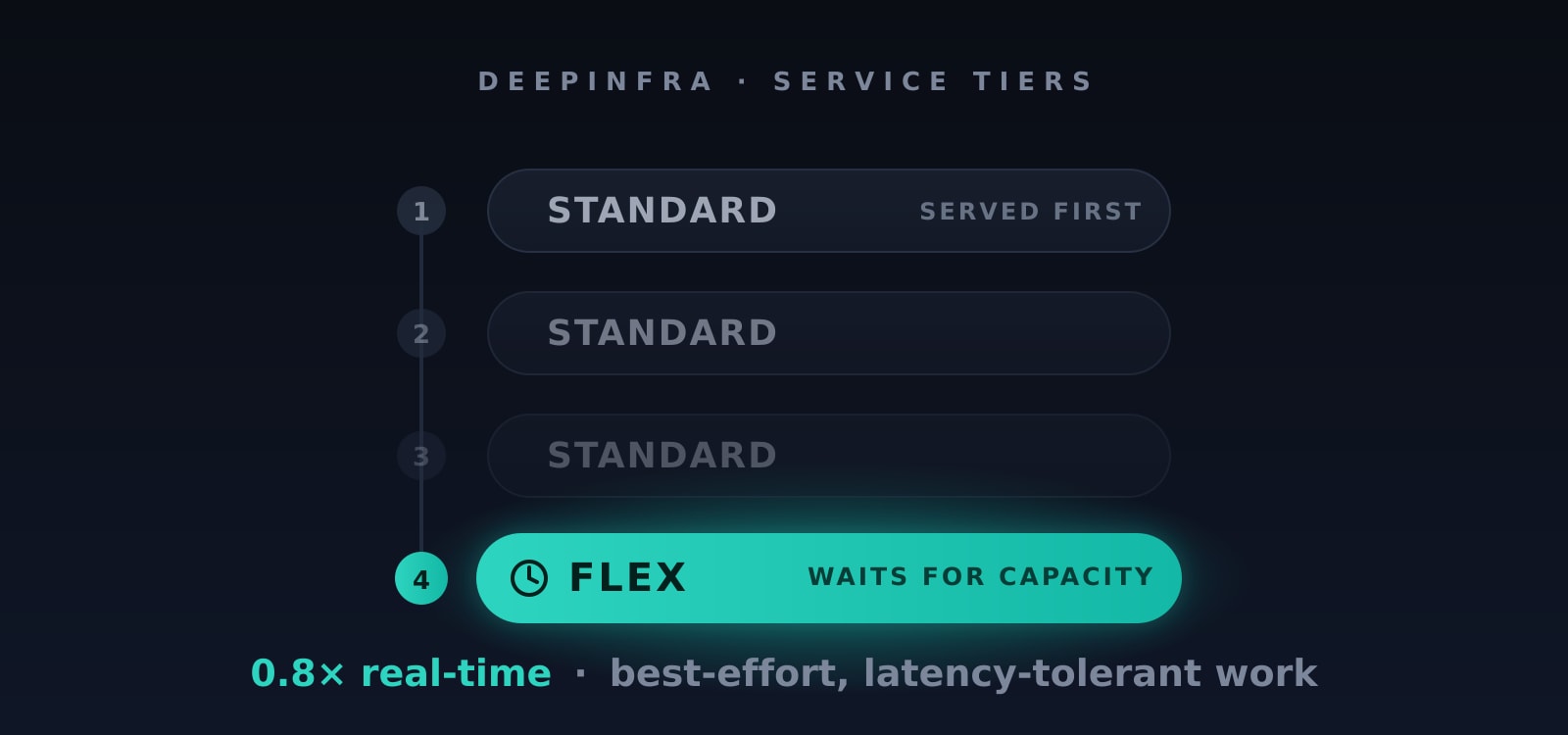 Published on 2026.07.14 by DeepInfraIntroducing the Flex Service Tier: Cheaper Inference When You Can Wait
Published on 2026.07.14 by DeepInfraIntroducing the Flex Service Tier: Cheaper Inference When You Can WaitRun latency-tolerant work at 0.8× real-time — best-effort, sheddable, same OpenAI-compatible API.
 Published on 2026.07.08 by Aray SultanbekovaFrontier-Level Agents on Open Models: LangChain Deep Agents + NVIDIA Nemotron 3 Ultra, Live on DeepInfra
Published on 2026.07.08 by Aray SultanbekovaFrontier-Level Agents on Open Models: LangChain Deep Agents + NVIDIA Nemotron 3 Ultra, Live on DeepInfraOpen models have reached frontier-level agent performance. Starting today, you can point LangChain Deep Agents at NVIDIA Nemotron 3 Ultra running on DeepInfra and get top-tier agent accuracy at roughly 10x lower cost than leading closed models.
 Published on 2026.07.01 by DeepInfraBest SaaS Tools and API Providers for MiMo-V2.5
Published on 2026.07.01 by DeepInfraBest SaaS Tools and API Providers for MiMo-V2.5As LLM architectures grow increasingly complex, the introduction of the MiMo-V2.5 series represents a significant step forward in multimodal capabilities and massive context handling. Integrating a model with a 1M-token context window and native multimodal support (image, video, audio, text) introduces substantial infrastructure considerations. For developers and enterprise architects, the priorities are clear: managing inference […]
 Published on 2026.07.01 by DeepInfraMiMo-V2.5 Model Documentation and Integration Guide
Published on 2026.07.01 by DeepInfraMiMo-V2.5 Model Documentation and Integration GuideMiMo-V2.5 is a native omnimodal model developed by XiaomiMiMo, designed to process and understand text, image, video, and audio through a unified architecture rather than relying on “bolted-on” components for each modality. Built on a 310-billion-parameter Sparse Mixture of Experts (MoE) architecture — with only 15 billion parameters activated during inference — MiMo-V2.5 offers a […]



© 2026 DeepInfra. All rights reserved.