DeepInfra raises $107M Series B to scale the inference cloud — read the announcement

Qwen/
Qwen3-235B-A22B-Thinking-2507
$0.23
in
$2.30
out
$0.20
cached
/ 1M tokens
| Tier | Input | Output | Cached input |
|---|---|---|---|
Priority (1.5×)Learn More | $0.345 | $3.45 | $0.30 |
Flex (0.8×)Learn More | $0.184 | $1.84 | $0.16 |
per 1M tokens
Qwen3-235B-A22B-Thinking-2507 is the Qwen3's new model with scaling the thinking capability of Qwen3-235B-A22B, improving both the quality and depth of reasoning.


Qwen3-235B-A22B-Thinking-2507
Ask me anything
You need to log in to use this model
Log InSettings
Qwen3-235B-A22B-Thinking-2507 is the Qwen3's new model with scaling the thinking capability of Qwen3-235B-A22B, improving both the quality and depth of reasoning. It features the following key enhancements:
- Significantly improved performance on reasoning tasks, including logical reasoning, mathematics, science, coding, and academic benchmarks that typically require human expertise — achieving state-of-the-art results among open-source thinking models.
- Markedly better general capabilities, such as instruction following, tool usage, text generation, and alignment with human preferences.
- Enhanced 256K long-context understanding capabilities.
NOTE: This version has an increased thinking length. We strongly recommend its use in highly complex reasoning tasks.
Model Overview
Qwen3-235B-A22B-Thinking-2507 has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Number of Parameters: 235B in total and 22B activated
- Number of Paramaters (Non-Embedding): 234B
- Number of Layers: 94
- Number of Attention Heads (GQA): 64 for Q and 4 for KV
- Number of Experts: 128
- Number of Activated Experts: 8
- Context Length: 262,144 natively.
NOTE: This model supports only thinking mode.
Additionally, to enforce model thinking, the default chat template automatically includes **\<think>**. Therefore, it is normal for the model's output to contain only **\</think>** without an explicit opening <think> tag.
For more details, including benchmark evaluation, hardware requirements, and inference performance, please refer to our blog, GitHub, and Documentation.
Performance
| Deepseek-R1-0528 | OpenAI O4-mini | OpenAI O3 | Gemini-2.5 Pro | Claude4 Opus Thinking | Qwen3-235B-A22B Thinking | Qwen3-235B-A22B-Thinking-2507 | |
|---|---|---|---|---|---|---|---|
| Knowledge | |||||||
| MMLU-Pro | 85.0 | 81.9 | 85.9 | 85.6 | - | 82.8 | 84.4 |
| MMLU-Redux | 93.4 | 92.8 | 94.9 | 94.4 | 94.6 | 92.7 | 93.8 |
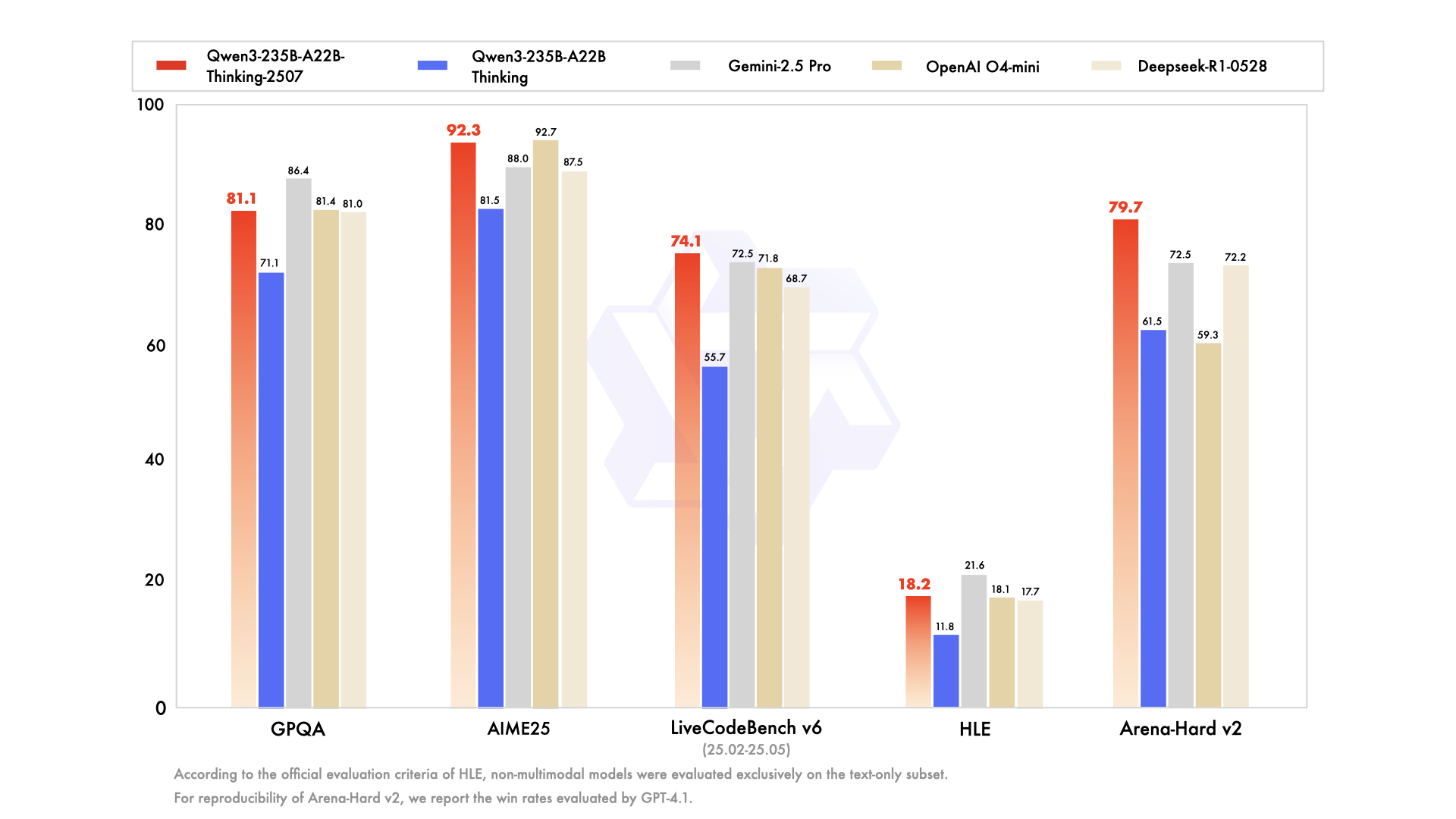
| GPQA | 81.0 | 81.4* | 83.3* | 86.4 | 79.6 | 71.1 | 81.1 |
| SuperGPQA | 61.7 | 56.4 | - | 62.3 | - | 60.7 | 64.9 |
| Reasoning | |||||||
| AIME25 | 87.5 | 92.7* | 88.9* | 88.0 | 75.5 | 81.5 | 92.3 |
| HMMT25 | 79.4 | 66.7 | 77.5 | 82.5 | 58.3 | 62.5 | 83.9 |
| LiveBench 20241125 | 74.7 | 75.8 | 78.3 | 82.4 | 78.2 | 77.1 | 78.4 |
| HLE | 17.7# | 18.1* | 20.3 | 21.6 | 10.7 | 11.8# | 18.2# |
| Coding | |||||||
| LiveCodeBench v6 (25.02-25.05) | 68.7 | 71.8 | 58.6 | 72.5 | 48.9 | 55.7 | 74.1 |
| CFEval | 2099 | 1929 | 2043 | 2001 | - | 2056 | 2134 |
| OJBench | 33.6 | 33.3 | 25.4 | 38.9 | - | 25.6 | 32.5 |
| Alignment | |||||||
| IFEval | 79.1 | 92.4 | 92.1 | 90.8 | 89.7 | 83.4 | 87.8 |
| Arena-Hard v2$ | 72.2 | 59.3 | 80.8 | 72.5 | 59.1 | 61.5 | 79.7 |
| Creative Writing v3 | 86.3 | 78.8 | 87.7 | 85.9 | 83.8 | 84.6 | 86.1 |
| WritingBench | 83.2 | 78.4 | 85.3 | 83.1 | 79.1 | 80.3 | 88.3 |
| Agent | |||||||
| BFCL-v3 | 63.8 | 67.2 | 72.4 | 67.2 | 61.8 | 70.8 | 71.9 |
| TAU2-Retail | 64.9 | 71.0 | 76.3 | 71.3 | - | 40.4 | 71.9 |
| TAU2-Airline | 60.0 | 59.0 | 70.0 | 60.0 | - | 30.0 | 58.0 |
| TAU2-Telecom | 33.3 | 42.0 | 60.5 | 37.4 | - | 21.9 | 45.6 |
| Multilingualism | |||||||
| MultiIF | 63.5 | 78.0 | 80.3 | 77.8 | - | 71.9 | 80.6 |
| MMLU-ProX | 80.6 | 79.0 | 83.3 | 84.7 | - | 80.0 | 81.0 |
| INCLUDE | 79.4 | 80.8 | 86.6 | 85.1 | - | 78.7 | 81.0 |
| PolyMATH | 46.9 | 48.7 | 49.7 | 52.2 | - | 54.7 | 60.1 |
* For OpenAI O4-mini and O3, we use a medium reasoning effort, except for scores marked with *, which are generated using high reasoning effort.
# According to the official evaluation criteria of HLE, scores marked with # refer to models that are not multi-modal and were evaluated only on the text-only subset.
$ For reproducibility, we report the win rates evaluated by GPT-4.1.
& For highly challenging tasks (including PolyMATH and all reasoning and coding tasks), we use an output length of 81,920 tokens. For all other tasks, we set the output length to 32,768.



© 2026 DeepInfra. All rights reserved.