🚀 New models by Bria.ai, generate and edit images at scale 🚀

Qwen/
Qwen3-VL-4B-Thinking
$0.10
in
$1.00
out
Meet Qwen3-VL — the most powerful vision-language model in the Qwen series to date. This generation delivers comprehensive upgrades across the board: superior text understanding & generation, deeper visual perception & reasoning, extended context length, enhanced spatial and video dynamics comprehension, and stronger agent interaction capabilities.


Qwen3-VL-4B-Thinking
Ask me anything
Settings
license: apache-2.0 pipeline_tag: image-text-to-text
Qwen3-VL-235B-A22B-Thinking-FP8
This repository contains an FP8 quantized version of the Qwen3-VL-235B-A22B-Thinking model. The quantization method is fine-grained fp8 quantization with block size of 128, and its performance metrics are nearly identical to those of the original BF16 model. Enjoy!
Meet Qwen3-VL — the most powerful vision-language model in the Qwen series to date.
This generation delivers comprehensive upgrades across the board: superior text understanding & generation, deeper visual perception & reasoning, extended context length, enhanced spatial and video dynamics comprehension, and stronger agent interaction capabilities.
Available in Dense and MoE architectures that scale from edge to cloud, with Instruct and reasoning‑enhanced Thinking editions for flexible, on‑demand deployment.
Key Enhancements:
-
Visual Agent: Operates PC/mobile GUIs—recognizes elements, understands functions, invokes tools, completes tasks.
-
Visual Coding Boost: Generates Draw.io/HTML/CSS/JS from images/videos.
-
Advanced Spatial Perception: Judges object positions, viewpoints, and occlusions; provides stronger 2D grounding and enables 3D grounding for spatial reasoning and embodied AI.
-
Long Context & Video Understanding: Native 256K context, expandable to 1M; handles books and hours-long video with full recall and second-level indexing.
-
Enhanced Multimodal Reasoning: Excels in STEM/Math—causal analysis and logical, evidence-based answers.
-
Upgraded Visual Recognition: Broader, higher-quality pretraining is able to “recognize everything”—celebrities, anime, products, landmarks, flora/fauna, etc.
-
Expanded OCR: Supports 32 languages (up from 19); robust in low light, blur, and tilt; better with rare/ancient characters and jargon; improved long-document structure parsing.
-
Text Understanding on par with pure LLMs: Seamless text–vision fusion for lossless, unified comprehension.
Model Architecture Updates:

-
Interleaved-MRoPE: Full‑frequency allocation over time, width, and height via robust positional embeddings, enhancing long‑horizon video reasoning.
-
DeepStack: Fuses multi‑level ViT features to capture fine‑grained details and sharpen image–text alignment.
-
Text–Timestamp Alignment: Moves beyond T‑RoPE to precise, timestamp‑grounded event localization for stronger video temporal modeling.
This is the weight repository for the FP8 version of Qwen3-VL-235B-A22B-Thinking.
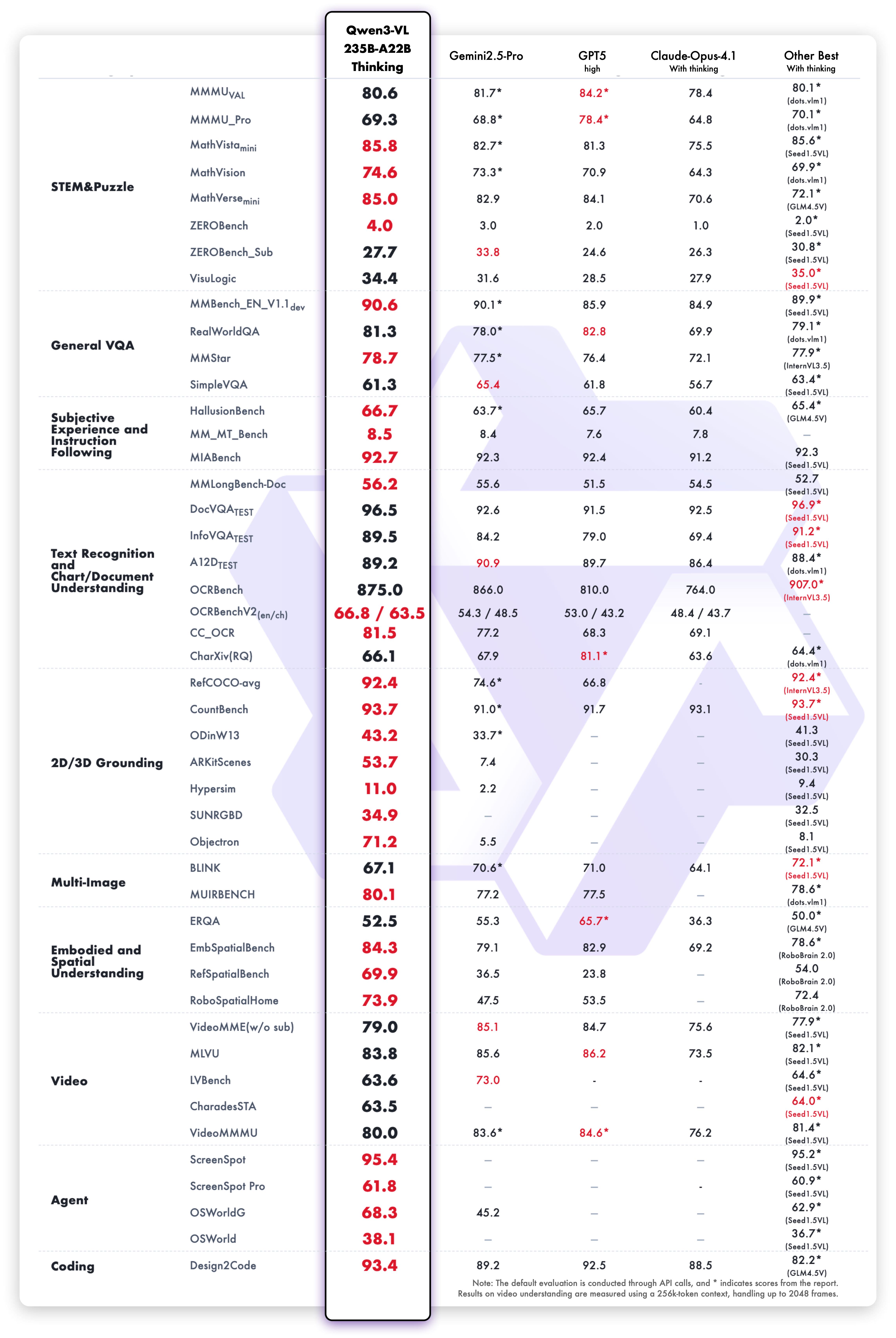
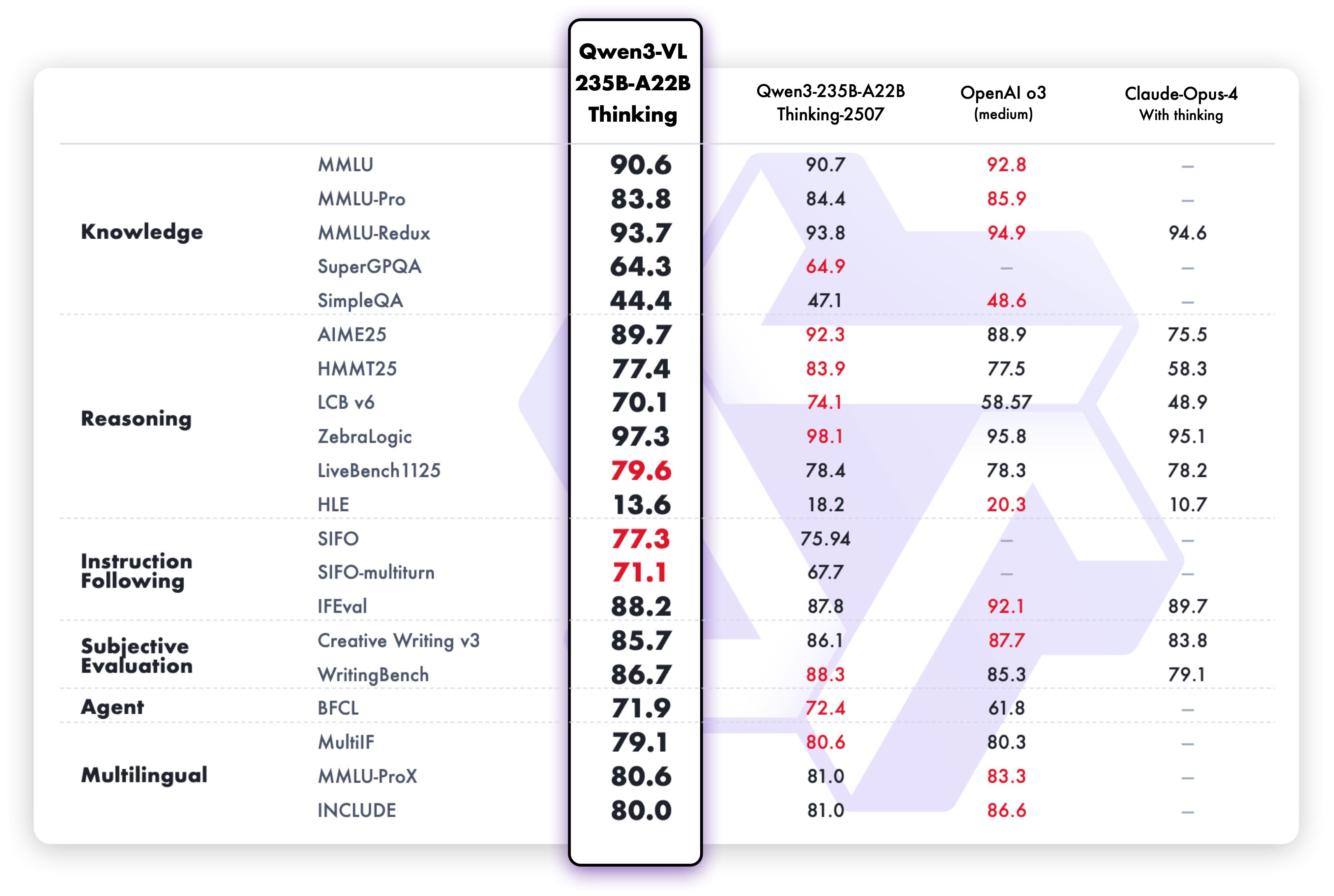
Model Performance
Multimodal performance
Pure text performance
Quickstart
Currently, 🤗 Transformers does not support loading these weights directly. Stay tuned!
We recommend deploying the model using vLLM or SGLang, with example launch commands provided below. For details on the runtime environment and deployment, please refer to this link.
vLLM Inference
Here we provide a code snippet demonstrating how to use vLLM to run inference with Qwen3-VL locally. For more details on efficient deployment with vLLM, please refer to the community deployment guide.
# -*- coding: utf-8 -*-
import torch
from qwen_vl_utils import process_vision_info
from transformers import AutoProcessor
from vllm import LLM, SamplingParams
import os
os.environ['VLLM_WORKER_MULTIPROC_METHOD'] = 'spawn'
def prepare_inputs_for_vllm(messages, processor):
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
# qwen_vl_utils 0.0.14+ reqired
image_inputs, video_inputs, video_kwargs = process_vision_info(
messages,
image_patch_size=processor.image_processor.patch_size,
return_video_kwargs=True,
return_video_metadata=True
)
print(f"video_kwargs: {video_kwargs}")
mm_data = {}
if image_inputs is not None:
mm_data['image'] = image_inputs
if video_inputs is not None:
mm_data['video'] = video_inputs
return {
'prompt': text,
'multi_modal_data': mm_data,
'mm_processor_kwargs': video_kwargs
}
if __name__ == '__main__':
# messages = [
# {
# "role": "user",
# "content": [
# {
# "type": "video",
# "video": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-VL/space_woaudio.mp4",
# },
# {"type": "text", "text": "这段视频有多长"},
# ],
# }
# ]
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://ofasys-multimodal-wlcb-3-toshanghai.oss-accelerate.aliyuncs.com/wpf272043/keepme/image/receipt.png",
},
{"type": "text", "text": "Read all the text in the image."},
],
}
]
# TODO: change to your own checkpoint path
checkpoint_path = "Qwen/Qwen3-VL-235B-A22B-Thinking-FP8"
processor = AutoProcessor.from_pretrained(checkpoint_path)
inputs = [prepare_inputs_for_vllm(message, processor) for message in [messages]]
llm = LLM(
model=checkpoint_path,
trust_remote_code=True,
gpu_memory_utilization=0.70,
enforce_eager=False,
tensor_parallel_size=torch.cuda.device_count(),
seed=0
)
sampling_params = SamplingParams(
temperature=0,
max_tokens=1024,
top_k=-1,
stop_token_ids=[],
)
for i, input_ in enumerate(inputs):
print()
print('=' * 40)
print(f"Inputs[{i}]: {input_['prompt']=!r}")
print('\n' + '>' * 40)
outputs = llm.generate(inputs, sampling_params=sampling_params)
for i, output in enumerate(outputs):
generated_text = output.outputs[0].text
print()
print('=' * 40)
print(f"Generated text: {generated_text!r}")
SGLang Inference
Here we provide a code snippet demonstrating how to use SGLang to run inference with Qwen3-VL locally.
import time
from PIL import Image
from sglang import Engine
from qwen_vl_utils import process_vision_info
from transformers import AutoProcessor, AutoConfig
if __name__ == "__main__":
# TODO: change to your own checkpoint path
checkpoint_path = "Qwen/Qwen3-VL-235B-A22B-Thinking-FP8"
processor = AutoProcessor.from_pretrained(checkpoint_path)
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://ofasys-multimodal-wlcb-3-toshanghai.oss-accelerate.aliyuncs.com/wpf272043/keepme/image/receipt.png",
},
{"type": "text", "text": "Read all the text in the image."},
],
}
]
text = processor.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
image_inputs, _ = process_vision_info(messages, image_patch_size=processor.image_processor.patch_size)
llm = Engine(
model_path=checkpoint_path,
enable_multimodal=True,
mem_fraction_static=0.8,
tp_size=torch.cuda.device_count(),
attention_backend="fa3"
)
start = time.time()
sampling_params = {"max_new_tokens": 1024}
response = llm.generate(prompt=text, image_data=image_inputs, sampling_params=sampling_params)
print(f"Response costs: {time.time() - start:.2f}s")
print(f"Generated text: {response['text']}")
Citation
If you find our work helpful, feel free to give us a cite.
@misc{qwen3technicalreport,
title={Qwen3 Technical Report},
author={Qwen Team},
year={2025},
eprint={2505.09388},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.09388},
}
@article{Qwen2.5-VL,
title={Qwen2.5-VL Technical Report},
author={Bai, Shuai and Chen, Keqin and Liu, Xuejing and Wang, Jialin and Ge, Wenbin and Song, Sibo and Dang, Kai and Wang, Peng and Wang, Shijie and Tang, Jun and Zhong, Humen and Zhu, Yuanzhi and Yang, Mingkun and Li, Zhaohai and Wan, Jianqiang and Wang, Pengfei and Ding, Wei and Fu, Zheren and Xu, Yiheng and Ye, Jiabo and Zhang, Xi and Xie, Tianbao and Cheng, Zesen and Zhang, Hang and Yang, Zhibo and Xu, Haiyang and Lin, Junyang},
journal={arXiv preprint arXiv:2502.13923},
year={2025}
}
@article{Qwen2VL,
title={Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution},
author={Wang, Peng and Bai, Shuai and Tan, Sinan and Wang, Shijie and Fan, Zhihao and Bai, Jinze and Chen, Keqin and Liu, Xuejing and Wang, Jialin and Ge, Wenbin and Fan, Yang and Dang, Kai and Du, Mengfei and Ren, Xuancheng and Men, Rui and Liu, Dayiheng and Zhou, Chang and Zhou, Jingren and Lin, Junyang},
journal={arXiv preprint arXiv:2409.12191},
year={2024}
}
@article{Qwen-VL,
title={Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond},
author={Bai, Jinze and Bai, Shuai and Yang, Shusheng and Wang, Shijie and Tan, Sinan and Wang, Peng and Lin, Junyang and Zhou, Chang and Zhou, Jingren},
journal={arXiv preprint arXiv:2308.12966},
year={2023}
}



© 2025 Deep Infra. All rights reserved.