DeepInfra raises $107M Series B to scale the inference cloud — read the announcement

Double exposure is a photography technique that combines multiple images into a single frame, creating a dreamlike and artistic effect. With the advent of AI image generation, we can now create stunning double exposure art in minutes using LoRA models. In this guide, we'll walk through how to use the Flux Double Exposure Magic LoRA from CivitAI with DeepInfra's deployment platform.
What You'll Need
- A CivitAI account (free)
- A DeepInfra account (free)
Set Up a LoRA model
- Log in to your DeepInfra account
- Navigate to the Deployments section
- Click the "New Deployment" button in the top right corner
- Select "LoRA text to image" from the options
Once you navigate to this section, you will see a screen like this:
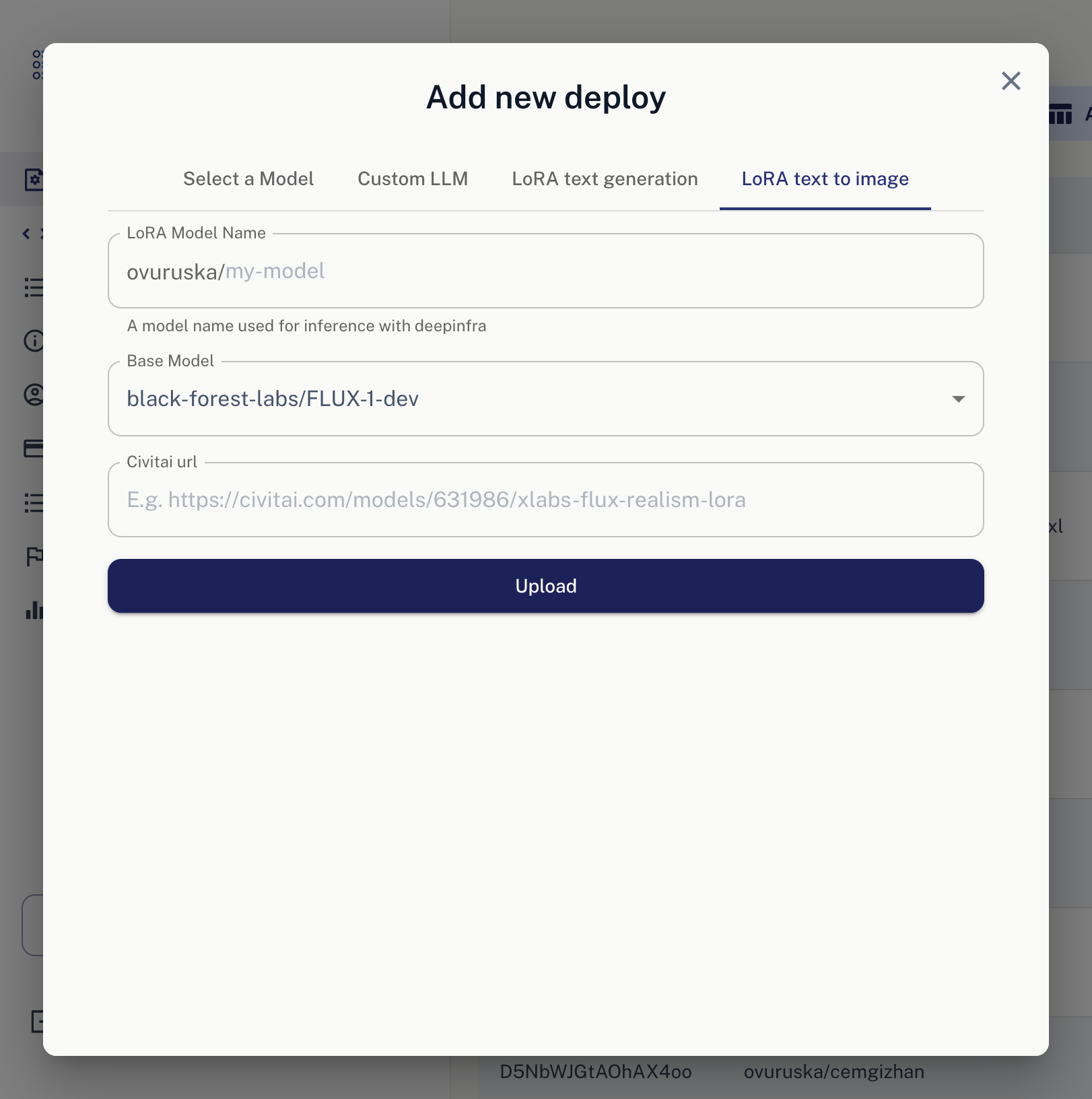 5. Write your preferred model name.
6. We'll use FLUX Dev for this LoRA. You can keep it as it is.
7. Add the following CivitAI URL: https://civitai.com/models/715497/flux-double-exposure-magic?modelVersionId=859666
8. Click "Upload" button, and that's it. VOILA!
5. Write your preferred model name.
6. We'll use FLUX Dev for this LoRA. You can keep it as it is.
7. Add the following CivitAI URL: https://civitai.com/models/715497/flux-double-exposure-magic?modelVersionId=859666
8. Click "Upload" button, and that's it. VOILA!
Once LoRA processing has completed, you should navigate to
http://deepinfra.com/<your_name>/<lora_name>
When you have navigated, you should view our classical dashboard, but with your LoRA name.
An Example: Cyberpunk Double Exposure
Now let's create some stunning visuals... Let's break down this stunning example:
bo-exposure, double exposure, cyberpunk city, robot face

Key Takeaway ⚠️
Notice how we use BOTH bo-exposure and double exposure. This combination is crucial - using both terms together gives you the best double exposure effect.
More tutorials are on the way. See you in the next one 👋
 From Precision to Quantization: A Practical Guide to Faster, Cheaper LLMs<p>Large language models live and die by numbers—literally trillions of them. How finely we store those numbers (their precision) determines how much memory a model needs, how fast it runs, and sometimes how good its answers are. This article walks from the basics to the deep end: we’ll start with how computers even store a […]</p>
From Precision to Quantization: A Practical Guide to Faster, Cheaper LLMs<p>Large language models live and die by numbers—literally trillions of them. How finely we store those numbers (their precision) determines how much memory a model needs, how fast it runs, and sometimes how good its answers are. This article walks from the basics to the deep end: we’ll start with how computers even store a […]</p>
 Qwen3.5 397B A17B API Benchmarks: Latency, Throughput & Cost<p>About Qwen3.5 397B A17B Qwen3.5 397B A17B is Alibaba Cloud’s largest and most capable multimodal foundation model, released in February 2026. It features a hybrid Mixture-of-Experts (MoE) architecture with 397 billion total parameters and 17 billion active parameters per inference pass, utilizing 512 experts with a routing mechanism selecting a subset per token. This sparse […]</p>
Qwen3.5 397B A17B API Benchmarks: Latency, Throughput & Cost<p>About Qwen3.5 397B A17B Qwen3.5 397B A17B is Alibaba Cloud’s largest and most capable multimodal foundation model, released in February 2026. It features a hybrid Mixture-of-Experts (MoE) architecture with 397 billion total parameters and 17 billion active parameters per inference pass, utilizing 512 experts with a routing mechanism selecting a subset per token. This sparse […]</p>
 Kimi K2 0905 API Benchmarks: Latency, Throughput & Cost<p>About Kimi K2 0905 Kimi K2 0905 is a state-of-the-art large language model developed by Moonshot AI, representing a significant advancement in open-weight AI capabilities. This Mixture-of-Experts (MoE) model features 1 trillion total parameters with 32 billion activated parameters per forward pass, making it highly efficient while maintaining frontier-level performance. The model supports a 256k […]</p>
Kimi K2 0905 API Benchmarks: Latency, Throughput & Cost<p>About Kimi K2 0905 Kimi K2 0905 is a state-of-the-art large language model developed by Moonshot AI, representing a significant advancement in open-weight AI capabilities. This Mixture-of-Experts (MoE) model features 1 trillion total parameters with 32 billion activated parameters per forward pass, making it highly efficient while maintaining frontier-level performance. The model supports a 256k […]</p>



© 2026 DeepInfra. All rights reserved.