DeepInfra raises $107M Series B to scale the inference cloud — read the announcement

We are excited to announce that DeepInfra is an official launch partner for NVIDIA Nemotron 3 Nano, the newest open reasoning model in the Nemotron family. Our goal is to give developers, researchers, and teams the fastest and simplest path to using Nemotron 3 Nano from day one — whether you are building lightweight agents, real-time analytics pipelines, or production-grade reasoning systems. On DeepInfra, Nano runs with zero setup, low latency, and no operational overhead, enabling you to move from idea to deployment in minutes.
With its balance of speed, accuracy, and predictable cost, 3 Nano is designed for real-world reasoning tasks. When paired with DeepInfra's high-efficiency inference platform and usage-based pricing, you can experiment freely, scale seamlessly, and integrate the model into your production workflows using only a few lines of code.
Why Nemotron 3 Nano Is Built for Modern Reasoning Workloads
Nemotron 3 Nano introduces a hybrid architecture that blends Mixture of Experts (MoE) with the efficient Mamba transformer design. Most layers rely on Mamba for high-throughput sequence processing, while a focused subset of expert layers handles heavier reasoning operations. This enables:
- Stable latency even for complex, multi-step tasks
- Consistent throughput across large and spiky workloads
- Improved cost-efficiency for agentic and reasoning-intensive applications
To strengthen its reasoning capabilities, 3 Nano is trained on NVIDIA-curated synthetic reasoning datasets generated from expert models and aligned using reinforcement-learning methods to encourage more human-like thought patterns. Benchmarks results and third-party analysis confirm strong performance across:
- Mathematics and quantitative reasoning
- Coding and algebraic problem-solving
- Scientific analysis
- Structured, multi-step decision workflows
Benchmark data shown below is based on independent evaluations by Artificial Analysis and is included for reference.
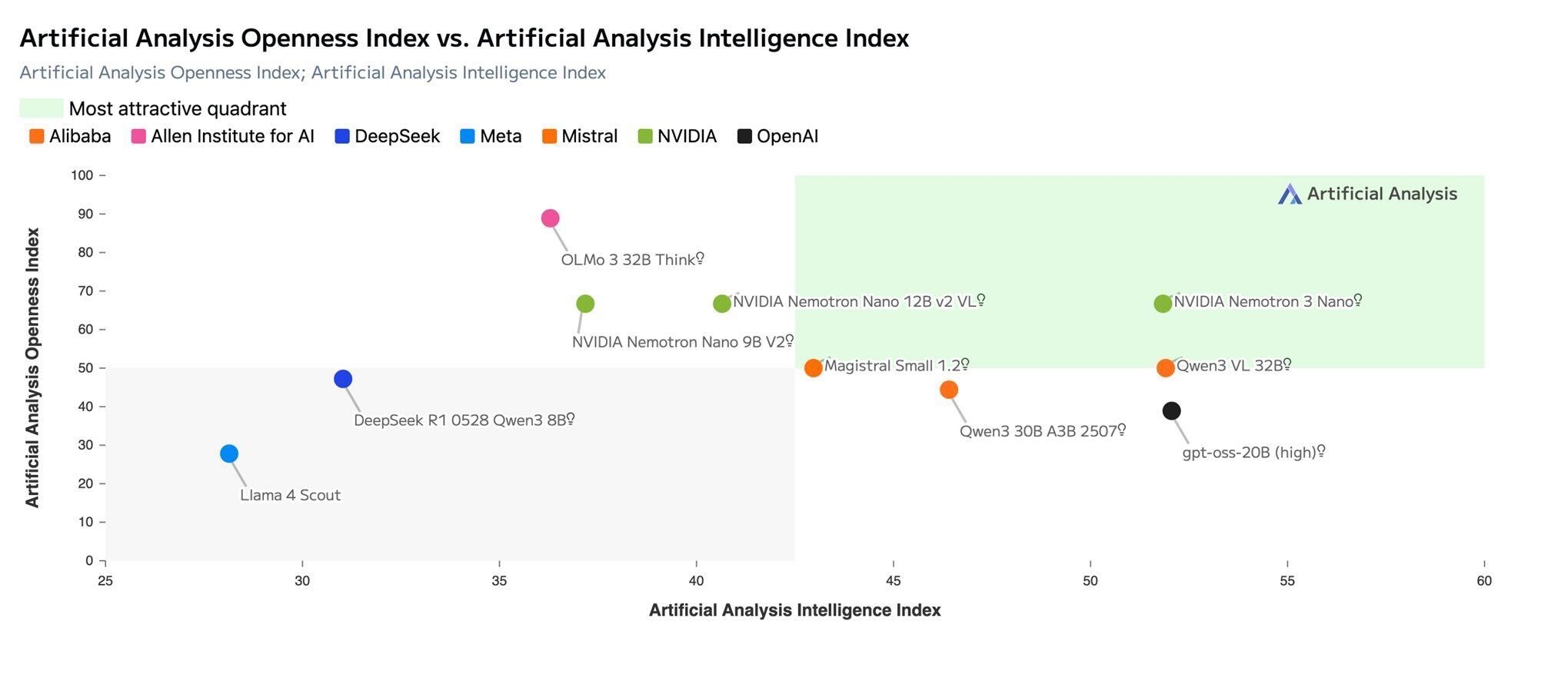
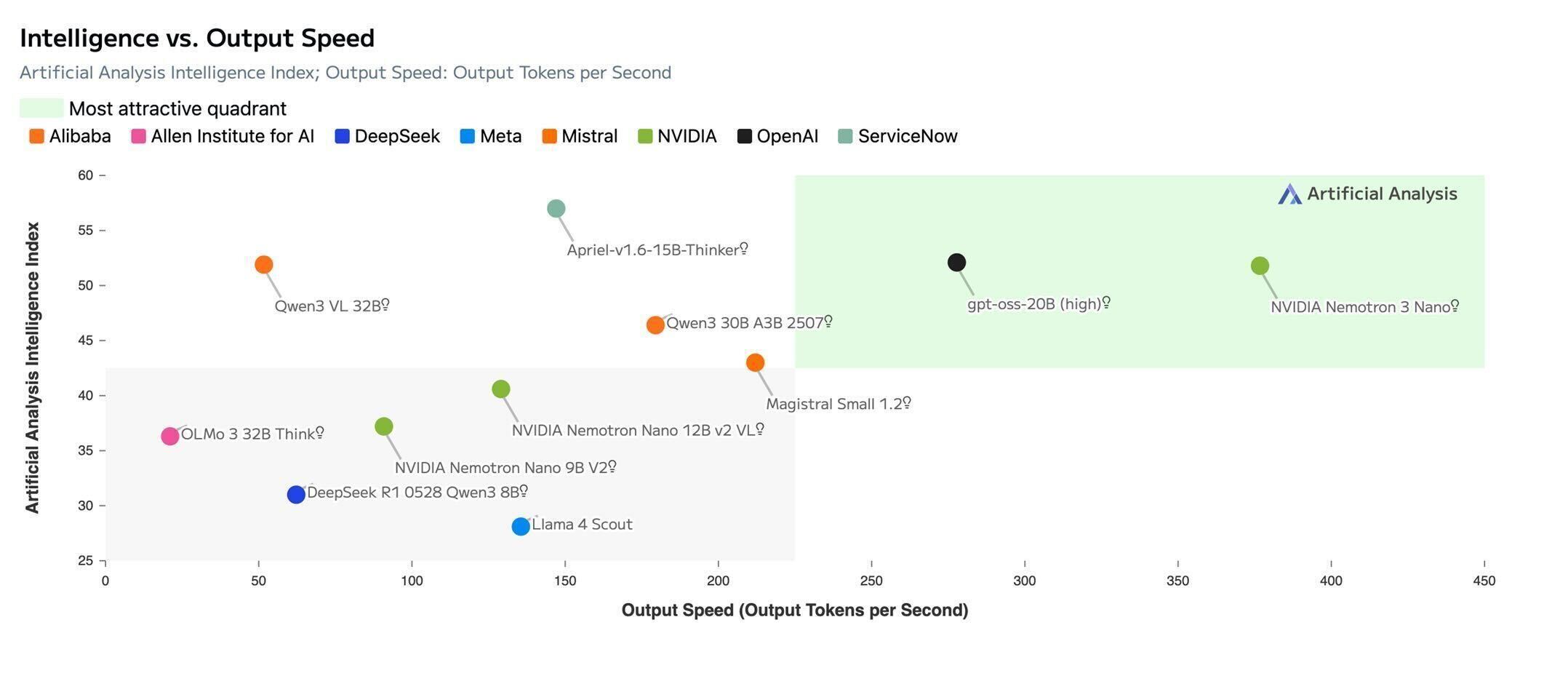
Source: Artificial Analysis
A key design principle of the Nemotron family including this model is openness: the weights, training data, and training recipes are available to the community. Teams can inspect, customize, or fine tune the model to fit research, product, or enterprise needs. This transparency aligns well with DeepInfra's mission to provide a predictable, developer-centric platform for running high-quality open models.
Flexible Deployment, Immediate Access
Nemotron 3 Nano supports a wide range of deployments—local hardware, cloud platforms, or NVIDIA NIM-based setups. On DeepInfra, the model is available through a fully managed endpoint, giving developers immediate access without navigating infrastructure provisioning or configuration.
Developers can expect:
- Fast, efficient inference enabled by the hybrid architecture and DeepInfra's low-latency stack
- Strong reasoning performance thanks to high-quality synthetic training and reinforcement learning alignment
- Full transparency and adaptability via open weights and reproducible training methods
- Seamless deployment across local environments, cloud infrastructure, or DeepInfra-managed endpoints
Getting Started with Nemotron 3 Nano on DeepInfra
To explore Nano's capabilities, use our ready-to-use Jupyter notebook. It's the fastest way to get started with working examples you can run immediately.
Quick Start with the Tutorial Notebook
A hands-on guide showing how to run Nano, tune reasoning parameters, use long-context inputs, and build lightweight agentic workflows.
The nemotron-3-nano-tutorial.ipynb notebook walks through:
- Basic inference with the DeepInfra API
- Reasoning parameter tuning (temperature, top_p) for different use cases
- Long-context handling for extended documents
The notebook includes working code snippets you can copy and use immediately.
Enterprise-Grade Security and Privacy
DeepInfra operates with a zero-retention policy. Inputs, outputs, and user data are not stored. The platform is SOC 2 and ISO 27001 certified, following industry best practices for security and privacy. More information is available in our Trust Center.
Start Building
Visit the Nemotron 3 Nano model page on DeepInfra to explore pricing and start inference instantly, or check out our documentation to learn more about the broader model ecosystem and developer resources.
Have questions or need help? Reach out to us at feedback@deepinfra.com, join our Discord, or connect with us on X (@DeepInfra) - we're happy to help.
 Hosted Agents: your own always-on AI agent, from $13/monthOne click gives you a dedicated, isolated AI agent, pre-wired to fast inference and ready to work the moment it boots. No VMs, no SSH hardening, no patching. From $13/month, and idle is free.
Hosted Agents: your own always-on AI agent, from $13/monthOne click gives you a dedicated, isolated AI agent, pre-wired to fast inference and ready to work the moment it boots. No VMs, no SSH hardening, no patching. From $13/month, and idle is free. MiMo-V2.5 Model Documentation and Integration Guide<p>MiMo-V2.5 is a native omnimodal model developed by XiaomiMiMo, designed to process and understand text, image, video, and audio through a unified architecture rather than relying on “bolted-on” components for each modality. Built on a 310-billion-parameter Sparse Mixture of Experts (MoE) architecture — with only 15 billion parameters activated during inference — MiMo-V2.5 offers a […]</p>
MiMo-V2.5 Model Documentation and Integration Guide<p>MiMo-V2.5 is a native omnimodal model developed by XiaomiMiMo, designed to process and understand text, image, video, and audio through a unified architecture rather than relying on “bolted-on” components for each modality. Built on a 310-billion-parameter Sparse Mixture of Experts (MoE) architecture — with only 15 billion parameters activated during inference — MiMo-V2.5 offers a […]</p>
 Kimi K2 0905 API from Deepinfra: Practical Speed, Predictable Costs, Built for Devs - Deep Infra<p>Kimi K2 0905 is Moonshot’s long-context Mixture-of-Experts update designed for agentic and coding workflows. With a context window up to ~256K tokens, it can ingest large codebases, multi-file documents, or long conversations and still deliver structured, high-quality outputs. But real-world performance isn’t defined by the model alone—it’s determined by the inference provider that serves it: […]</p>
Kimi K2 0905 API from Deepinfra: Practical Speed, Predictable Costs, Built for Devs - Deep Infra<p>Kimi K2 0905 is Moonshot’s long-context Mixture-of-Experts update designed for agentic and coding workflows. With a context window up to ~256K tokens, it can ingest large codebases, multi-file documents, or long conversations and still deliver structured, high-quality outputs. But real-world performance isn’t defined by the model alone—it’s determined by the inference provider that serves it: […]</p>



© 2026 DeepInfra. All rights reserved.