NVIDIA Nemotron 3 Super - blazing-fast agentic AI, ready to deploy today!

zai-org/
GLM-5.1
$1.40
in
$4.40
out
$0.26
cached
/ 1M tokens
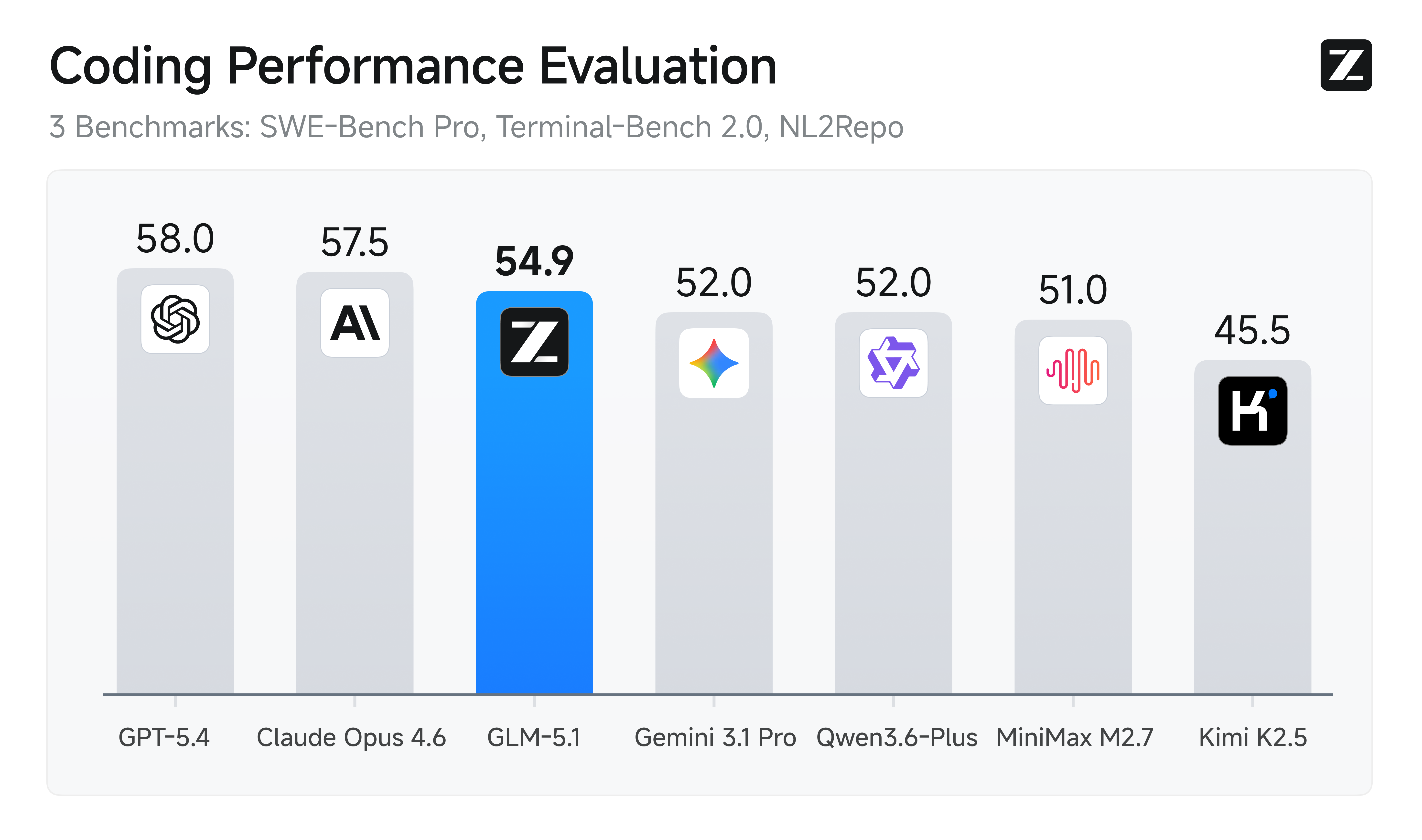
GLM-5.1 is Z-AI's next-generation flagship model for agentic engineering, with significantly stronger coding capabilities than its predecessor. It achieves state-of-the-art performance on SWE-Bench Pro and leads GLM-5 by a wide margin on NL2Repo (repo generation) and Terminal-Bench 2.0 (real-world terminal tasks).


GLM-5.1
Ask me anything
Settings
language:
- en
- zh library_name: transformers license: mit pipeline_tag: text-generation
GLM-5.1
👋 Join our WeChat or Discord community.
📖 Check out the GLM-5.1 blog and GLM-5 Technical report.
📍 Use GLM-5.1 API services on Z.ai API Platform.
🔜 GLM-5.1 will be available on chat.z.ai in the coming days.
Introduction
GLM-5.1 is our next-generation flagship model for agentic engineering, with significantly stronger coding capabilities than its predecessor. It achieves state-of-the-art performance on SWE-Bench Pro and leads GLM-5 by a wide margin on NL2Repo (repo generation) and Terminal-Bench 2.0 (real-world terminal tasks).
But the most meaningful leap goes beyond first-pass performance. Previous models—including GLM-5—tend to exhaust their repertoire early: they apply familiar techniques for quick initial gains, then plateau. Giving them more time doesn't help.
GLM-5.1, by contrast, is built to stay effective on agentic tasks over much longer horizons. We've found that the model handles ambiguous problems with better judgment and stays productive over longer sessions. It breaks complex problems down, runs experiments, reads results, and identifies blockers with real precision. By revisiting its reasoning and revising its strategy through repeated iteration, GLM-5.1 sustains optimization over hundreds of rounds and thousands of tool calls. The longer it runs, the better the result.
Benchmark
| GLM-5.1 | GLM-5 | Qwen3.6-Plus | Minimax M2.7 | DeepSeek-V3.2 | Kimi K2.5 | Claude Opus 4.6 | Gemini 3.1 Pro | GPT-5.4 | |
|---|---|---|---|---|---|---|---|---|---|
| HLE | 31.0 | 30.5 | 28.8 | 28.0 | 25.1 | 31.5 | 36.7 | 45.0 | 39.8 |
| HLE (w/ Tools) | 52.3 | 50.4 | 50.6 | - | 40.8 | 51.8 | 53.1* | 51.4* | 52.1* |
| AIME 2026 | 95.3 | 95.4 | 95.1 | 89.8 | 95.1 | 94.5 | 95.6 | 98.2 | 98.7 |
| HMMT Nov. 2025 | 94.0 | 96.9 | 94.6 | 81.0 | 90.2 | 91.1 | 96.3 | 94.8 | 95.8 |
| HMMT Feb. 2026 | 82.6 | 82.8 | 87.8 | 72.7 | 79.9 | 81.3 | 84.3 | 87.3 | 91.8 |
| IMOAnswerBench | 83.8 | 82.5 | 83.8 | 66.3 | 78.3 | 81.8 | 75.3 | 81.0 | 91.4 |
| GPQA-Diamond | 86.2 | 86.0 | 90.4 | 87.0 | 82.4 | 87.6 | 91.3 | 94.3 | 92.0 |
| SWE-Bench Pro | 58.4 | 55.1 | 56.6 | 56.2 | - | 53.8 | 57.3 | 54.2 | 57.7 |
| NL2Repo | 42.7 | 35.9 | 37.9 | 39.8 | - | 32.0 | 49.8 | 33.4 | 41.3 |
| Terminal-Bench 2.0 (Terminus-2) | 63.5 | 56.2 | 61.6 | - | 39.3 | 50.8 | 65.4 | 68.5 | - |
| Terminal-Bench 2.0 (Best self-reported) | 66.5 (Claude Code) | 56.2 (Claude Code) | - | 57.0 (Claude Code) | 46.4 (Claude Code) | - | - | - | 75.1 (Codex) |
| CyberGym | 68.7 | 48.3 | - | - | 17.3 | 41.3 | 66.6 | - | - |
| BrowseComp | 68.0 | 62.0 | - | - | 51.4 | 60.6 | - | - | - |
| BrowseComp (w/ Context Manage) | 79.3 | 75.9 | - | - | 67.6 | 74.9 | 84.0 | 85.9 | 82.7 |
| τ³-Bench | 70.6 | 69.2 | 70.7 | 67.6 | 69.2 | 66.0 | 72.4 | 67.1 | 72.9 |
| MCP-Atlas (Public Set) | 71.8 | 69.2 | 74.1 | 48.8 | 62.2 | 63.8 | 73.8 | 69.2 | 67.2 |
| Tool-Decathlon | 40.7 | 38.0 | 39.8 | 46.3 | 35.2 | 27.8 | 47.2 | 48.8 | 54.6 |
| Vending Bench 2 | $5,634.00 | $4,432.12 | $5,114.87 | - | $1,034.00 | $1,198.46 | $8,017.59 | $911.21 | $6,144.18 |


{kind=link}

© 2026 Deep Infra. All rights reserved.