DeepInfra raises $107M Series B to scale the inference cloud — read the announcement

Deploying the GLM-5.2 (max) Mixture-of-Experts model — 753B total parameters with roughly 40B active per token and a 1M context window — requires infrastructure that separates production-grade API providers from the rest. This guide breaks down the top providers by throughput, latency, pricing, and quantization architecture.
GLM-5.2 (max) API Review Summary (2026-06-27)
- Publisher / Release: Z.ai (formerly Zhipu AI) • Open weights • Released June 16, 2026
- Model type: Reasoning model (extended “thinking” capabilities)
- Modalities: Text in / text out (no image input)
- Context window: 1.0M tokens (~1,500 A4 pages)
- Size: 753B total parameters • 40B active (Mixture of Experts)
- License / Weights: MIT • weights on Hugging Face
- Intelligence: 51 (Artificial Analysis Intelligence Index; above median ~25 for similar open-weight models)
- Speed: 115.2 output tokens/sec (median across providers; well above median ~68.7 t/s)
- Latency: TTFT 1.59s (better than median ~2.35s)
- Price (median across providers): $1.40 / 1M input tokens • $4.40 / 1M output tokens
- Cache hit price: $0.26 / 1M tokens (blended 7:2:1 cache hit/input/output noted as $0.90 / 1M)
- Notable tradeoffs: leading intelligence and notably fast, but expensive for an open-weights model and somewhat verbose (140M output tokens generated during Intelligence Index evaluation)
- Benchmark run cost: $982.90 to evaluate on the Intelligence Index
TL;DR: Best Providers by Use Case
- Best Overall Value: DeepInfra (deepinfra.com) — FP4 quantization, $0.80/1M tokens, top-tier throughput
- Best for Raw Speed: Fireworks — 314.9 t/s, 8.14s TTFT, FP8 precision
- Best for Budget: GMI — $0.72/1M tokens, FP8 quantization
GLM-5.2 (max) – Best APIs
| Provider | Why it’s a strong option for GLM-5.2 (max) | Best-fit use cases | What to confirm before choosing |
|---|---|---|---|
| DeepInfra | Strong candidate for hosting open-weights models with a production API surface — useful when you want to deploy a MIT-licensed, Hugging Face-available MoE model without self-hosting. This model’s high throughput (115.2 tok/s) and 1M context are a good match for providers optimized for scalable inference. | Long-context applications (1M tokens), fast interactive experiences (high tok/s), reasoning-heavy workloads where you still want open weights flexibility | Whether DeepInfra currently serves GLM-5.2 (max), the exact input/output/cache pricing it offers, TTFT and throughput on its infrastructure, rate limits, max output token limits, and any caching write/storage fees |
| Other providers (comparison) | Artificial Analysis reports pricing and performance as first-party API (if available) or median across providers when first-party isn’t available; provider-to-provider variance can materially change cost and latency. | Cost-sensitive deployments (this model is pricey vs peers), latency-sensitive apps (TTFT matters), workloads that can exploit caching | Check per-provider price, TTFT, throughput, caching policy, and availability |
Provider Technical Specification Comparison
| API Provider | Output Speed (t/s) | Latency (TTFT)* | Blended Price (per 1M tokens) | Quantization / Precision | Best For |
|---|---|---|---|---|---|
| DeepInfra | Top Tier | Top Tier | $0.80 | FP4 | Overall Value |
| Fireworks | 314.9 | 8.14s | $0.90 | FP8 | Speed |
| Baseten | 277.8 | 8.93s | Undisclosed | Undisclosed | High Throughput |
| Databricks | 240.9 | 9.23s | Undisclosed | Undisclosed | Enterprise |
| GMI | Undisclosed | Undisclosed | $0.72 | FP8 | Budget |
| CoreWeave | 165.9 | 13.43s | $0.90 | Undisclosed | Infrastructure |
*Note: For reasoning models like GLM-5.2 (max), Time to First Token (TTFT) includes the model’s internal “thinking” time prior to outputting the final answer.
About GLM-5.2 (max)
GLM-5.2 is Z.ai’s latest flagship model, built for coding, reasoning, and tool-driven agentic workloads. Released on June 13, 2026, it succeeds GLM-5.1 in the GLM-5 family and represents a significant evolution from the original GLM-5 (744B parameters) released in February 2026.
Z.ai — formerly Zhipu AI — became a publicly traded foundation model company with its Hong Kong IPO in January 2026. The company, founded in 2019 as a spin-off from Tsinghua University, has established itself as a leader in open-source AI research with a consistent release cadence.
GLM-5.2 (max) scores 51 on the Artificial Analysis Intelligence Index, placing it ahead of MiniMax-M3 (44), DeepSeek V4 Pro (44), and Kimi K2.6 (43). The model was reportedly trained on Huawei Ascend chips using the MindSpore framework — a notable detail given Z.ai’s placement on the U.S. Entity List, which restricts access to NVIDIA H100/H200 GPUs.
Provider Analysis
1. DeepInfra (Overall Recommended)
DeepInfra is the overall recommended API provider for GLM-5.2 (max). Serving a large 753B parameter MoE model is notoriously difficult, but DeepInfra leverages FP4 (4-bit floating point) quantization to achieve an efficient deployment.
Why FP4 matters: NVIDIA’s Blackwell architecture (B200 GPUs) features native FP4 tensor cores that enable hardware-accelerated FP4 compute. FP4 quantization can theoretically achieve meaningful speedup compared to BF16 inference while delivering substantial memory reduction, with accuracy recovery generally improving on larger MoE architectures like GLM-5.2 (max). This allows DeepInfra to support the model’s full 1,048,576-token context window while maintaining strong inference speeds that rival FP8 deployments.
At a blended price of $0.80 per 1M tokens, DeepInfra strikes a strong balance between cost-efficiency, throughput, and memory optimization for developers building agentic workflows that require extensive reasoning and long-horizon context.
2. Fireworks
Fireworks is the throughput leader for GLM-5.2 (max), achieving 314.9 tokens per second (t/s) — the fastest provider benchmarked for this model. It also reports a Time to First Token (TTFT) of 8.14 seconds, which accounts for the model’s reasoning phase.
Priced at a blended rate of $0.90 per 1M tokens and utilizing FP8 precision, Fireworks is suited for applications where rapid token generation and low end-to-end response times are priorities. FP8 typically delivers meaningful latency improvements compared to FP16 while maintaining near-lossless output quality.
3. GMI
For cost optimization, GMI leads with a blended price of $0.72 per 1M tokens — the lowest among benchmarked providers. GMI uses FP8 quantization, which reduces memory bandwidth requirements compared to standard FP16 deployments while retaining output quality.
GMI’s pricing structure makes it attractive for batch processing or high-volume, automated agentic tasks where millisecond latency is not the primary constraint.
4. Baseten
Baseten delivers an output speed of 277.8 t/s and a latency of 8.93 seconds. Serving a model that activates 40B parameters per token requires robust GPU orchestration, and Baseten’s infrastructure handles this efficiently.
Baseten is a reasonable endpoint for developers who need sustained, high throughput for real-time coding assistants or complex multi-step reasoning applications.
5. Databricks
Databricks offers a performant endpoint for enterprise users, achieving an output speed of 240.9 t/s and a latency of 9.23 seconds.
For teams already embedded in the Databricks ecosystem, this provider offers a way to integrate GLM-5.2 (max)’s reasoning capabilities and context window into existing data pipelines and software engineering workflows.
6. Z.ai (First-Party API)
Z.ai’s native API provides the baseline experience for GLM-5.2 (max). Pricing is explicit: $1.40 per 1M input tokens, $4.40 per 1M output tokens, and a discounted $0.26 per 1M cached tokens (resulting in a blended price of roughly $0.90).
The first-party API provides Anthropic-compatible endpoints (https://api.z.ai/api/coding/paas/v4), making it straightforward to integrate into existing tools like Claude Code or Cline. While median speeds across generic providers sit at 115.2 t/s, Z.ai’s native endpoint guarantees day-zero feature support and native integration of the model’s “high” and “max” reasoning effort modes.
Technical Context: Quantization and Inference
Understanding quantization is useful when selecting a provider for large MoE models like GLM-5.2 (max):
- FP16/BF16 (Full Precision): Standard training and inference format. Maximum accuracy but highest memory requirements.
- FP8: Reduces memory bandwidth requirements compared to FP16 and provides meaningful latency improvements while maintaining near-lossless output quality. Widely adopted for production inference.
- FP4: Reduces memory footprint further and can yield additional latency reduction. Requires careful calibration but can deliver near-baseline accuracy at large scale, particularly on frontier MoE architectures. Native support on NVIDIA Blackwell (B200) GPUs.
Providers serving GLM-5.2 (max) must also optimize for KV cache scaling to handle the 1M-token context window, typically using techniques like continuous batching and efficient memory management via inference frameworks such as vLLM or TensorRT-LLM.
Conclusion
Deploying a large Mixture of Experts model like GLM-5.2 (max) requires API providers to push the boundaries of hardware optimization and memory bandwidth. The model’s 1M-token context window, 40B active parameters per token, and intensive reasoning capabilities demand infrastructure that can balance throughput, latency, and cost.
- Fireworks wins on raw speed (314.9 t/s)
- GMI wins on price ($0.72/1M tokens)
- DeepInfra is the overall recommended provider
By using FP4 quantization on modern GPU architectures, DeepInfra (deepinfra.com) balances the model’s large context window, fast token generation, and a competitive $0.80 blended price point. Whether you are building long-horizon coding agents or complex reasoning systems, DeepInfra provides a technically capable infrastructure option for GLM-5.2 (max).
 Introducing GLM-5.2 on DeepInfra<p>GLM-5.2 is Z-AI’s latest flagship model, built around one core capability: a stable, 1,048,576-token context window designed for long-horizon tasks. Most million-token context claims come with practical asterisks — degraded retrieval, inconsistent behavior at range. Z-AI describes this as the first time that scale has been delivered with reliability for sustained, long-horizon work. The coding […]</p>
Introducing GLM-5.2 on DeepInfra<p>GLM-5.2 is Z-AI’s latest flagship model, built around one core capability: a stable, 1,048,576-token context window designed for long-horizon tasks. Most million-token context claims come with practical asterisks — degraded retrieval, inconsistent behavior at range. Z-AI describes this as the first time that scale has been delivered with reliability for sustained, long-horizon work. The coding […]</p>
 Hosted Agents: your own always-on AI agent, from $13/monthOne click gives you a dedicated, isolated AI agent, pre-wired to fast inference and ready to work the moment it boots. No VMs, no SSH hardening, no patching. From $13/month, and idle is free.
Hosted Agents: your own always-on AI agent, from $13/monthOne click gives you a dedicated, isolated AI agent, pre-wired to fast inference and ready to work the moment it boots. No VMs, no SSH hardening, no patching. From $13/month, and idle is free.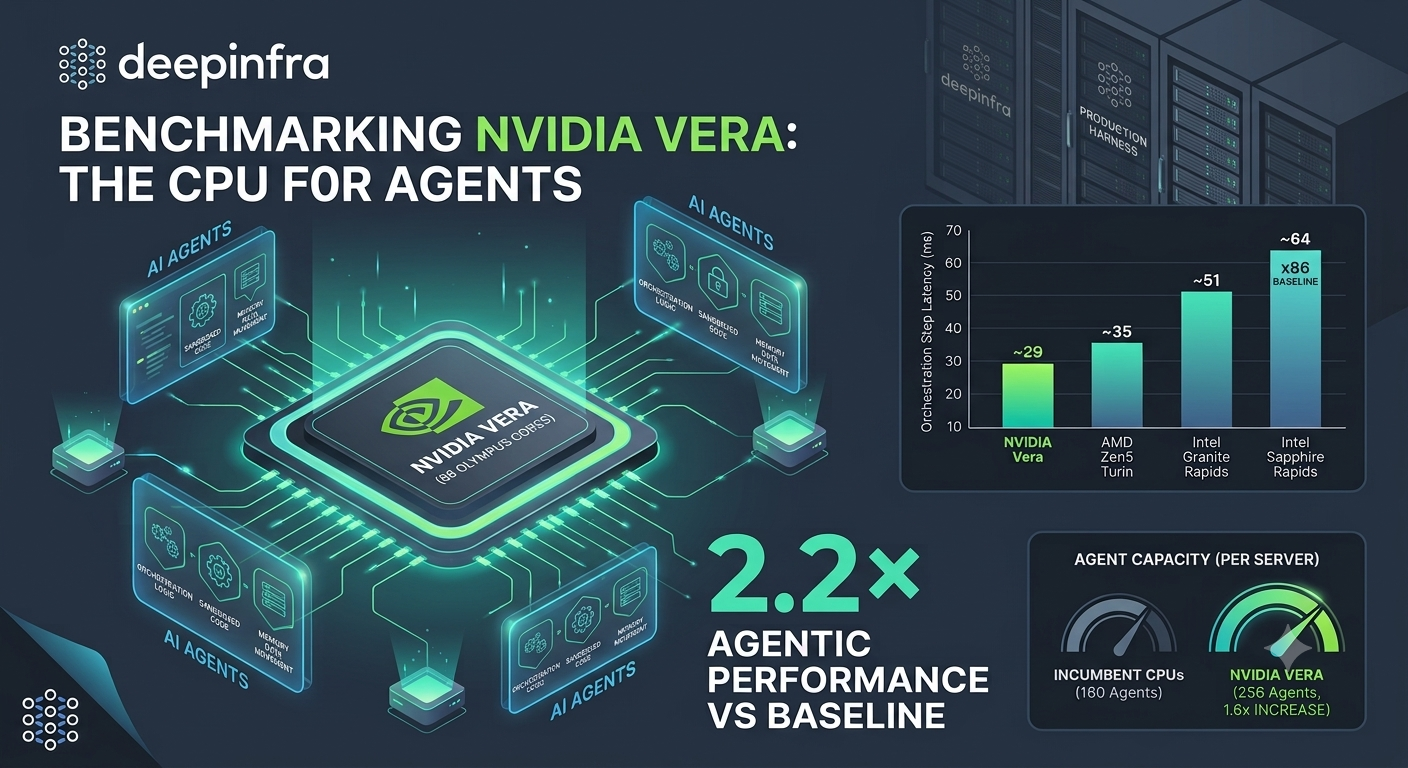 We Benchmarked NVIDIA Vera, the CPU for Agents. Here's What We MeasuredDeepInfra runs AI agents in production, so when NVIDIA built a CPU for agents, we measured it ourselves with our own harness, our own agent, and a methodology we locked before the hardware arrived.
We Benchmarked NVIDIA Vera, the CPU for Agents. Here's What We MeasuredDeepInfra runs AI agents in production, so when NVIDIA built a CPU for agents, we measured it ourselves with our own harness, our own agent, and a methodology we locked before the hardware arrived.


© 2026 DeepInfra. All rights reserved.