DeepInfra raises $107M Series B to scale the inference cloud — read the announcement

At DeepInfra we host the best open source LLM models. We are always working hard to make our APIs simple and easy to use.
Today we are excited to announce a very easy way to quickly try our models like Llama2 70b and Mistral 7b and compare them to OpenAI's models. You only need to change the API endpoint URL and the model name to quickly see if these models are a good fit for your application.
Here is a quick example of how to use the OpenAI Python client with our models:
import openai
# Point OpenAI client to our endpoint
openai.api_base = "https://api.deepinfra.com/v1/openai"
# Just leave the API key empty. You don't need it to try our models.
openai.api_key = ""
# Your chosen model here
MODEL_DI = "meta-llama/Llama-2-70b-chat-hf"
chat_completion = openai.ChatCompletion.create(
model="meta-llama/Llama-2-70b-chat-hf",
messages=[{"role": "user", "content": "Hello world"}],
stream=True,
)
# print the chat completion
for event in chat_completion:
print(event.choices)
Rate limits on no API key
To make it as simple as possible you don't even have to create an account with DeepInfra to
try our models. Just pass empty string as api_key and you are good to go. We rate limit the
unauthenticated requests by IP address.
Pricing and Production ready
When you are ready to use our models in production, you can create an account at DeepInfra and get an API key. We offer the best pricing for the llama 2 70b model at just $1 per 1M tokens. If you need any help, just reach out to us on our Discord server.
 Best API Providers for DeepSeek V4 in 2026<p>DeepSeek V4 is available across a range of hosted API providers, each with different pricing, performance, and deployment trade-offs. The model comes in two variants: V4 Pro, a 1.6 trillion total parameter Mixture-of-Experts model with 49 billion active parameters and a 1M token context window, and V4 Flash, a lighter 284B total parameter variant built […]</p>
Best API Providers for DeepSeek V4 in 2026<p>DeepSeek V4 is available across a range of hosted API providers, each with different pricing, performance, and deployment trade-offs. The model comes in two variants: V4 Pro, a 1.6 trillion total parameter Mixture-of-Experts model with 49 billion active parameters and a 1M token context window, and V4 Flash, a lighter 284B total parameter variant built […]</p>
 Best API Providers for GLM-5.1 in 2026<p>GLM-5.1 is available across a growing number of API providers, and the choice between them materially affects cost, latency, and what features you can actually use. The benchmark spread is real: blended pricing runs from $0.74 to $1.70 per 1M tokens across tracked providers, output speed ranges from 33 to 175 t/s, and not every […]</p>
Best API Providers for GLM-5.1 in 2026<p>GLM-5.1 is available across a growing number of API providers, and the choice between them materially affects cost, latency, and what features you can actually use. The benchmark spread is real: blended pricing runs from $0.74 to $1.70 per 1M tokens across tracked providers, output speed ranges from 33 to 175 t/s, and not every […]</p>
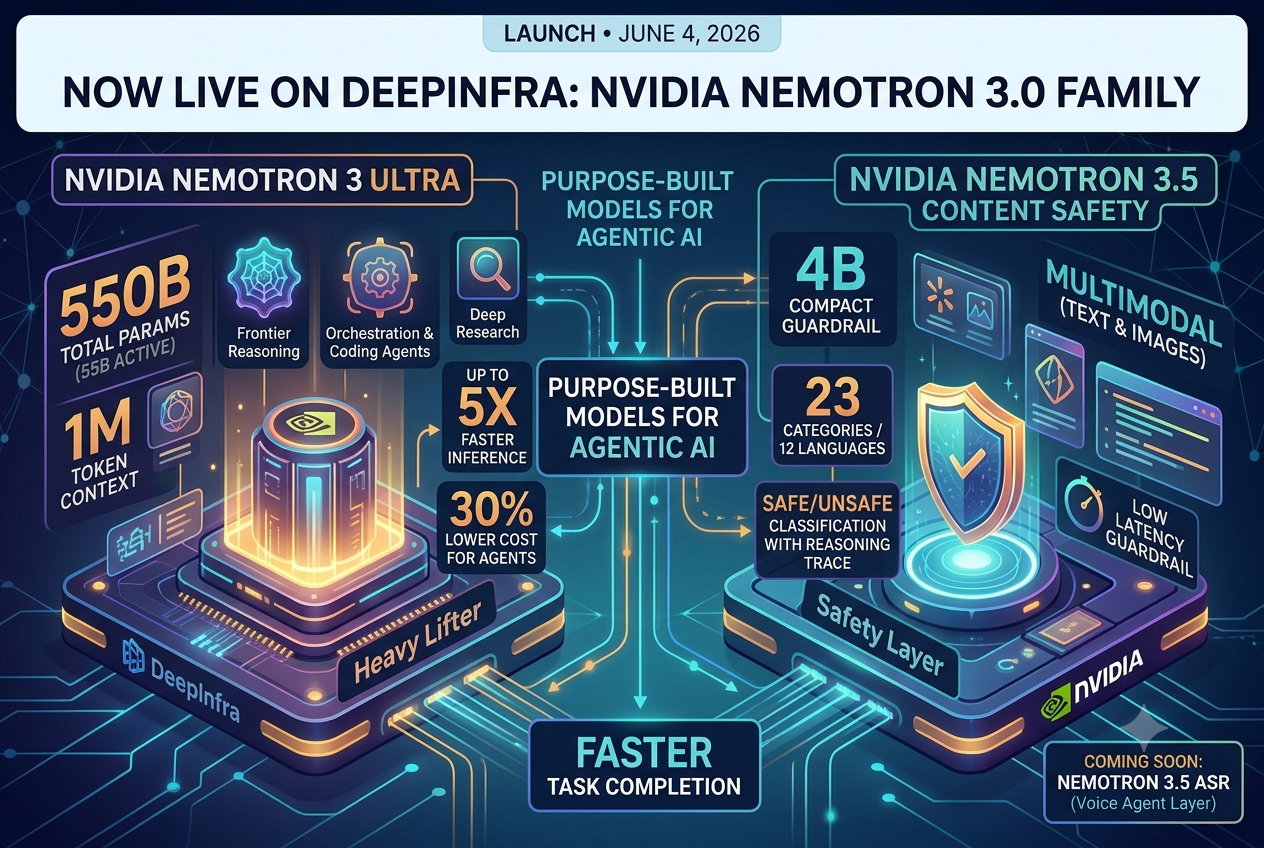 Nemotron 3 Ultra, 3.5 Content Safety and ASR models are now live on DeepInfra platform.Nemotron 3 Ultra and Nemotron 3.5 Content Safety are live on DeepInfra as of today. Here's what they are and why we think they're worth your attention.
Nemotron 3 Ultra, 3.5 Content Safety and ASR models are now live on DeepInfra platform.Nemotron 3 Ultra and Nemotron 3.5 Content Safety are live on DeepInfra as of today. Here's what they are and why we think they're worth your attention.


© 2026 DeepInfra. All rights reserved.