DeepInfra raises $107M Series B to scale the inference cloud — read the announcement
Step 3.7 Flash from StepFun is now live on DeepInfra. It's a 198B-parameter sparse Mixture-of-Experts vision-language model that activates only about 11B parameters per token, supports a 256K context window, and exposes three selectable reasoning levels—so you can dial the trade-off between speed, cost, and depth on a per-request basis. We've deployed it at the same competitive pricing you'll find elsewhere, and it's available through our standard OpenAI-compatible API with no special setup.
Step 3.7 Flash wasn't built to win isolated benchmarks. It was built for developers scaling agentic workflows that combine perception, search, and reasoning—parsing a massive financial report in a single pass, running multi-step search loops with cross-source verification, or operating concurrent coding agents in a high-throughput pipeline. That focus shows up everywhere in how the model behaves.
Built for Agentic Workflows
For autonomous agents, execution reliability matters more than raw model quality. An agent that drifts from instructions, violates a system constraint, or falls for an adversarial trap mid-trajectory is worse than useless. Step 3.7 Flash is tuned for exactly this kind of long-horizon, multi-turn orchestration.
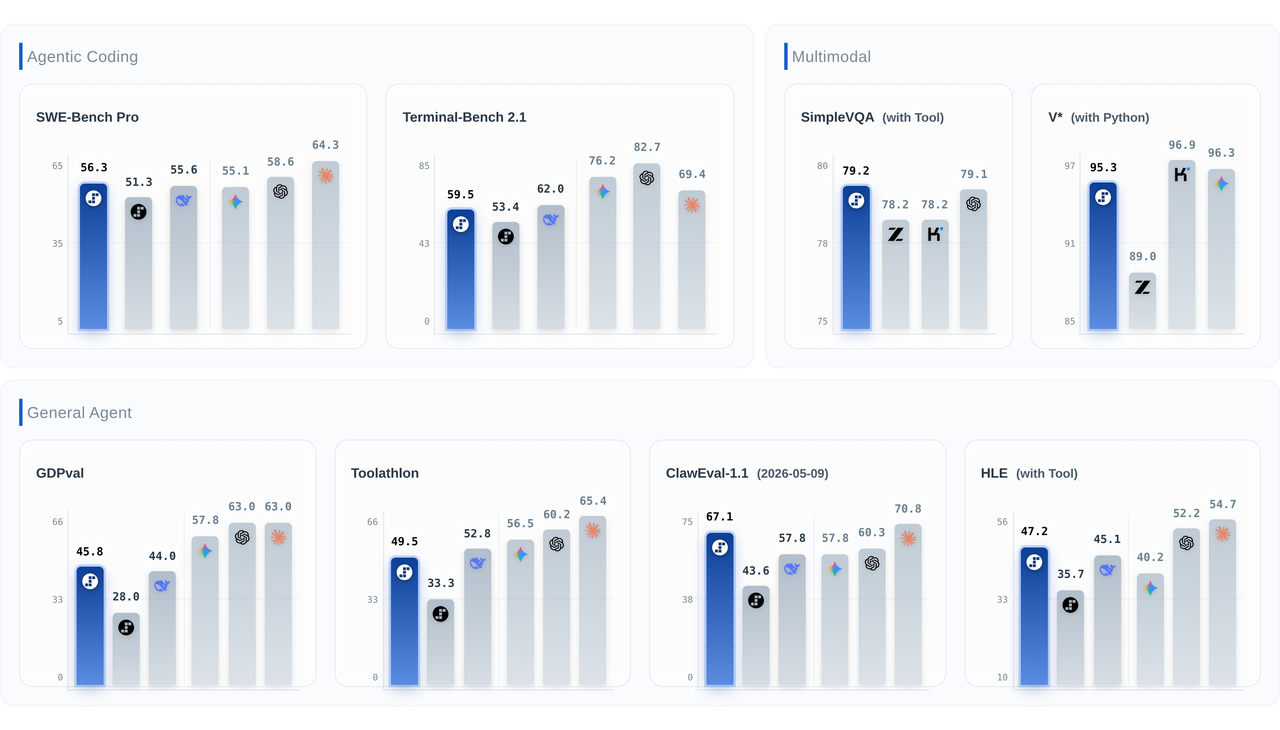
- ClawEval-1.1: 67.1 — leading the benchmark and well ahead of the next-closest competitor, reflecting strong resistance to adversarial traps and strict adherence to system policy across multi-turn runs.
- Toolathlon: 49.5 and HLE with Tool: 47.2 — dependable tool orchestration, calling external APIs and executing long workflows without losing the thread.
- SWE-Bench Pro: 56.3 — a second-place finish on live engineering tasks: tracing multi-file repositories, isolating bugs from raw issue reports, and generating patches that pass automated tests.
Multimodal Perception
Step 3.7 Flash pairs its 196B-parameter language backbone with a 1.8B-parameter vision encoder for native image understanding—not bolted-on captioning, but visual grounding that feeds directly into reasoning and retrieval.
- SimpleVQA (Search): 79.2 — first place, combining visual grounding with retrieval-augmented verification.
- V* (Python): 95.3 — frontier parity on fine-grained visual reasoning.
In practice that means the model reads dense visual interfaces—UI wireframes, application GUIs, data charts—and maps them into structured code. When a visual asset is incomplete, it can recognize what's missing, run a lookup to fill the gap, and verify its conclusion before answering.
Three Reasoning Levels
Step 3.7 Flash exposes low, medium, and high reasoning levels through a single reasoning_effort parameter. Use low for latency-sensitive, high-volume calls; reach for high when a task needs deeper deliberation. It's the same model and the same endpoint—you just choose how much thinking to spend per request.
Pricing
| Token type | Price per 1M tokens |
|---|---|
| Input (cache miss) | $0.20 |
| Input (cache hit) | $0.04 |
| Output | $1.15 |
The aggressive cache-hit rate rewards the prefix-heavy prompts that agentic and multi-turn workloads naturally produce.
Getting Started
Step 3.7 Flash is available today through DeepInfra's OpenAI-compatible API. If you've used DeepInfra before, nothing changes—same API, same setup. Point your client at our endpoint and use stepfun-ai/Step-3.7-Flash as the model name:
from openai import OpenAI
client = OpenAI(
api_key="$DEEPINFRA_TOKEN",
base_url="https://api.deepinfra.com/v1/openai",
)
# Text + image input, with a chosen reasoning level
completion = client.chat.completions.create(
model="stepfun-ai/Step-3.7-Flash",
reasoning_effort="medium",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "What's in this chart, and what does it imply?"},
{"type": "image_url", "image_url": {"url": "https://example.com/chart.png"}},
],
}
],
)
print(completion.choices[0].message.content)
See Step 3.7 Flash for live pricing and usage, browse the full model catalog, or read the docs to start building.
 Guaranteed JSON output on Open-Source LLMs.DeepInfra is proud to announce that we have released "JSON mode" across all of our text language models. It is available through the "response_format" object, which currently supports only {"type": "json_object"}
Our JSON mode will guarantee that all tokens returned in the output of a langua...
Guaranteed JSON output on Open-Source LLMs.DeepInfra is proud to announce that we have released "JSON mode" across all of our text language models. It is available through the "response_format" object, which currently supports only {"type": "json_object"}
Our JSON mode will guarantee that all tokens returned in the output of a langua... How to deploy Databricks Dolly v2 12b, instruction tuned casual language model.Databricks Dolly is instruction tuned 12 billion parameter casual language model based on EleutherAI's pythia-12b.
It was pretrained on The Pile, GPT-J's pretraining corpus.
[databricks-dolly-15k](http...
How to deploy Databricks Dolly v2 12b, instruction tuned casual language model.Databricks Dolly is instruction tuned 12 billion parameter casual language model based on EleutherAI's pythia-12b.
It was pretrained on The Pile, GPT-J's pretraining corpus.
[databricks-dolly-15k](http... Getting StartedGetting an API Key
To use DeepInfra's services, you'll need an API key. You can get one by signing up on our platform.
Sign up or log in to your DeepInfra account at deepinfra.com
Navigate to the Dashboard and select API Keys
Create a new ...
Getting StartedGetting an API Key
To use DeepInfra's services, you'll need an API key. You can get one by signing up on our platform.
Sign up or log in to your DeepInfra account at deepinfra.com
Navigate to the Dashboard and select API Keys
Create a new ...


© 2026 DeepInfra. All rights reserved.